大模型应用-期末
-
大模型时代所提出的 AI 开发新模式可以概括成两步
- 预训练
- 目标:让模型从海量无标注文本中学习语言的通用规律、知识和世界模式。
- 方法:采用“自监督学习”。例如,掩码语言模型或“预测下一个词”的任务。通过在海量数据上进行这个基础训练,模型学会了语法、事实、逻辑推理等通用能力。
- 结果:得到一个“基础模型”(如GPT、BERT)。它知识渊博,但尚未对齐任何具体任务,像一个刚完成通识教育的毕业生
- 微调:
- 目标:让基础模型适应特定的下游任务
- 方法:在预训练好的“基础模型”上,使用高质量、有标注的小规模任务数据继续训练。模型参数会根据新任务进行小幅、精准的调整
- 常见技术:
- 全量微调:调整模型所有参数,效果好但成本高。
- 高效微调:如LoRA,只调整少量新增参数,高效且节省资源。
- 结果:得到一个“专家模型”。它在特定任务上表现优异,同时保留了预训练阶段学到的全部通用知识。
- 预训练
-
涌现能力:大模型的涌现能力是指当模型规模(参数量、数据量、计算量)达到一定阈值时,突然出现的一些在较小模型中不存在的新能力。这些能力并非通过显式编程或专门训练获得,而是随着规模增长"自然涌现"出来的。典型涌现能力包括:
- 复杂推理:小模型只能做简单问答,大模型突然能进行多步逻辑推理、数学计算、代码生成等复杂任务。
- 上下文学习:仅通过几个示例就能理解新任务,无需额外训练(few-shot learning)。
- 指令遵循:能理解并执行自然语言指令,完成各种开放域任务。
-
微调的优缺点
- 优点
- 高效利用预训练知识:微调在预训练模型基础上进行,继承了模型从海量数据中学到的通用语言能力、世界知识和推理能力,避免了从零训练的巨大成本。
- 任务适应性强:通过少量高质量标注数据,就能让通用模型快速适应特定领域或任务,如医疗问答、法律咨询、代码生成等,实现"举一反三"。
- 训练成本相对较低:相比预训练需要海量计算资源,微调只需调整部分参数,计算成本和时间都大幅降低。
- 缺点
- 灾难性遗忘风险:微调过程中,模型可能过度拟合新任务数据,导致遗忘预训练阶段学到的通用知识,影响在其他任务上的表现。
- 数据质量要求高:微调效果严重依赖标注数据的质量和数量,数据偏差或噪声会直接影响模型性能。
- 过拟合风险:当微调数据量较小时,模型容易过拟合到训练数据,在测试集上表现不佳。
- 优点
-
LoRA 微调为什么能达到了和全参微调相似的效果:核心原因在于低秩假设。大模型微调过程中的参数更新矩阵具有低秩特性,即虽然全参微调需要更新数十亿参数,但实际有效的更新信息可以用一个低维空间来近似表示。LoRA将参数更新ΔW分解为两个小矩阵的乘积BA,其中 r 远小于原始维度。这样既大幅减少了参数量(通常仅为全参微调的0.1%-1%),又保持了信息表达能力。
-
大语言模型的定义:大语言模型 (Large Language Model, LLM) 是一种基于深度学习的人工智能模型,它能够从海量的文本数据中学习并理解人类语言的模式和规则.它包含数千亿(或更多)参数,通过复杂的神经网络结构来模拟人类的语言处理能力
-
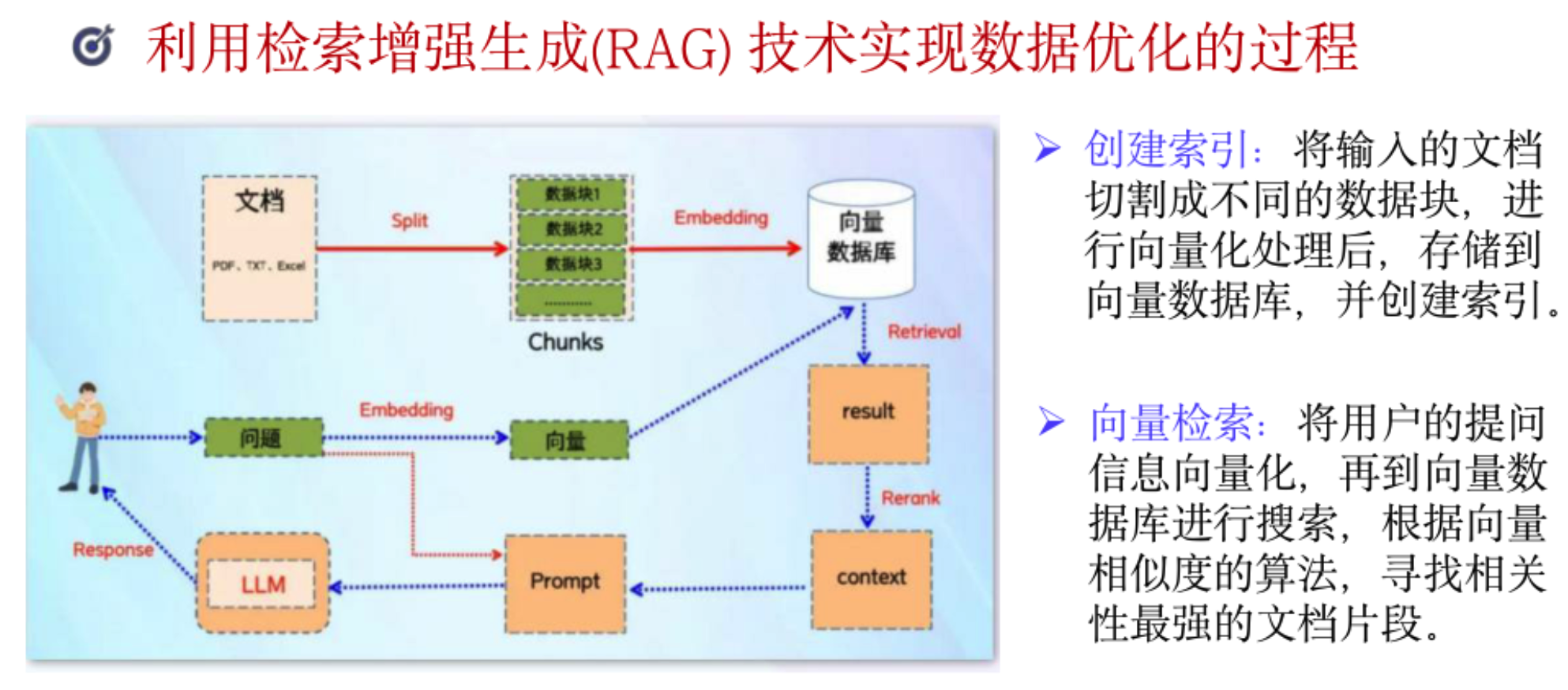
RAG (检索增强生成)是一种结合信息检索和文本生成的大模型技术,通过从外部知识库检索相关信息来增强大模型的生成能力。RAG将传统的大语言模型生成过程分为两个阶段:
- 检索阶段
- 根据用户查询,从外部知识库(如文档数据库、网页、知识图谱)中检索最相关的信息片段
- 使用向量检索技术,将查询和文档都转换为向量表示,通过相似度计算找到最匹配的内容
- 增强生成阶段
- 将检索到的相关信息与用户查询一起输入给大语言模型
- 模型基于检索内容生成更准确、更可靠的回答
- 检索阶段
-
数据库小助手,怎么做,怎么进一步增强
-
用户提示词的系统提示词区别
- 系统提示词是开发者或管理员设置的,用于定义AI的角色定位、行为准则和对话风格
- 用户提示词是用户每次输入的具体问题或指令,用于触发AI的即时响应。它决定了单次对话的内容方向,可以是问题、命令、续写请求等。用户提示词是动态的,每次对话都会变化
-
大模型的问题
- 幻觉问题:大模型会生成看似合理但实际错误或不存在的信息,即"一本正经地胡说八道"。
- 时效性问题:大模型的知识存在时间滞后,无法获取训练截止日期后的最新信息。
- 数据安全问题:大模型可能泄露训练数据中的敏感信息,或生成有害内容。
-
外挂和内挂的区别
- 外挂:在模型推理时实时检索外部知识库,将检索到的信息与用户查询一起输入给模型。
- 实时性:知识库可以随时更新,模型能获取最新信息
- 灵活性:可以连接多个知识源(数据库、API、网页等)
- 可解释性:可以展示检索到的来源文档
- 代表技术:RAG(检索增强生成)
- 内挂:通过微调或继续训练,将知识直接编码到模型参数中。
- 离线性:知识在训练阶段就固化到模型权重中
- 速度快:推理时无需外部检索,响应更快
- 稳定性:不受网络或外部服务影响
- 代表技术:全参微调、LoRA、Adapter等
- 外挂:在模型推理时实时检索外部知识库,将检索到的信息与用户查询一起输入给模型。
-
Agent 有哪些功能,结合案例描述
- 感知:Agent通过多模态输入(文本、图像、语音等)理解用户意图和环境状态,包括解析用户查询、识别文件内容、理解上下文等。
- 记忆(短期,长期):Agent具备短期记忆(对话上下文)和长期记忆(知识库、历史记录),能够记住用户偏好、任务状态和过往经验。
- 决策规划:Agent 根据目标制定执行计划,分解复杂任务为可执行的子任务,并动态调整策略。
- 行动:Agent通过调用工具(API、代码执行、文件操作等)执行具体任务,并验证执行结果。
-
一个完整的智能客服Agent工作流程:
- 感知:接收用户问题"我的订单为什么还没发货?"
- 记忆:调取用户历史订单信息、物流规则
- 决策规划:判断需要查询订单状态、检查物流信息、解释延迟原因
- 行动:调用订单系统API获取状态,查询物流信息,生成回复"您的订单已打包,预计明天发货,请耐心等待"
-
Agent 的自主性:Agent的自主性是指智能体在无人干预的情况下,能够独立感知环境、制定目标、规划任务并执行行动的能力。这种自主性体现在多个层面,从简单的任务执行到复杂的战略规划。
-
LangChain是一个用于开发大语言模型应用的框架,它通过链式调用将多个组件连接起来,构建复杂的AI应用。
- 模型地址和api_key
- 在LangChain中,配置模型地址和API密钥是连接大语言模型服务的基础步骤。以OpenAI为例,配置方式如下:
- openai_api_key:必填,用于身份验证
- model_name:指定使用的模型,如"gpt-3.5-turbo"、"gpt-4"等
- base_url:如果需要使用代理或自定义API地址
- 模型地址和api_key
-
temperature参数(0-2)
- temperature=0:确定性最高,模型每次都会生成相同或非常相似的输出。适合需要可重复结果、事实性回答的场景,如代码生成、数学计算。
- temperature=0.5-0.8:平衡性,在创造性和准确性之间取得平衡。适合大多数对话和内容生成任务,既有一定创造性又不会过于随机。
- temperature=1.0:默认值,保持模型训练时的原始随机性。
- temperature=1.5-2.0:高度随机,模型会生成更具创造性、多样性的内容,但可能包含不准确或离题的内容。适合创意写作、头脑风暴等需要发散思维的场景。
-
ReAct Agent
- ReAct(Reasoning + Acting)是一种结合推理和行动的Agent框架,让大语言模型能够通过思维链(Chain-of-Thought)进行推理,并调用外部工具执行具体操作。
- ReAct将Agent的工作流程分为两个交替进行的阶段:
- 推理(Reasoning)
- 模型生成思考过程,分析当前情况
- 确定下一步需要做什么
- 评估可用的工具和资源
- 行动(Acting)
- 调用外部工具执行具体操作
- 获取执行结果
- 观察环境变化
- 推理(Reasoning)
-
Coze 常用节点
- 选择器
- 大模型
- 循环
- 知识库检索
- 按行切割
- Coze知识库,火山知识库
- 图像生成
- 变量聚合
- 意图识别
-
MaxKB 工作流程一般可以分成三步
- 添加模型
- 创建知识库
- 创建应用