数据库笔记 - 期末
绪论
数据库的 4 个基本概念
- 数据(data):符号记录,数据的含义称为语义;
- 数据库(DataBase,DB):长期存储在计算机内、有组织的可共享的大量数据的集合;
- 数据库管理系统(DataBase management System,DBMS):位于用户和OS之间的一个基础软件;
包括几个功能:数据库定义语言DDL,数据库操纵语言DML,数据库的建立和维护等等。 - 数据库系统(DataBase System,DBS):由DB、DBMS、应用程序和数据库管理员DBA组成的系统。
数据库管理的三个阶段
- 人工管理阶段:没有OS,数据不保存,不共享,没有独立性,冗余度大
- 文件系统阶段:有文件系统,数据保存,不共享,独立性差,冗余度大
- 数据库系统阶段:数据结构化,共享性高,冗余度小,具有高度的物理独立性和一定的逻辑独立性
数据模型
数据模型是对现实世界数据特征的抽象,是数据库的核心和基础
数据模型分为几类
- 概念模型
- 逻辑模型
- 物理模型
概念模型(Conceptual Data Model)
用于需求分析阶段,描述用户的需求、数据之间的逻辑关系。
最经典的有:ER 模型(实体–联系模型)
- 实体(Entity):学生、课程、教师
- 属性(Attribute):学号、姓名、成绩
- 联系(Relationship):选课、指导、教授
逻辑模型(Logical Data Model)
描述数据在数据库系统中的逻辑组织方式。
主要有三类传统模型:
(1) 层次模型(Hierarchical Model)
-
树形结构
-
典型系统:IBM 的 IMS
-
特点:查询快,但结构太严格(父子关系固定)
(2) 网状模型(Network Model)
-
图结构
-
可有多对多复杂关系
-
灵活但结构复杂,不易维护
(3) 关系模型(Relational Model)
- 使用二维表描述数据
- 由 Codd 提出
- 典型:MySQL、PostgreSQL、SQL Server
物理模型(Physical Data Model)
描述数据在实际存储中的结构和存取方式。
- 存储结构:堆文件、顺序文件、索引文件
- 存取路径:B+树索引、哈希索引
- 数据页、块、缓冲区管理
作用:让 DBMS 高效存储和检索数据。
数据库系统的三级模式结构
数据库系统为了实现数据抽象、数据独立性,将数据库结构分为三层:外模式,模式,内模式
外模式(External Schema)
又叫用户模式或子模式(Subschema)。
作用:面向用户或应用程序,描述某个用户能看到的数据。
-
每个用户都有自己的外模式
-
外模式可以只包含部分字段
-
具有 安全性(隐藏不该看的数据)
学生数据库中有表 Student(学号, 姓名, 年龄, 成绩, 专业)
教务处用户只需要:(学号, 姓名, 成绩)
学工办可能只需要:(学号, 姓名, 专业)
概念模式(Conceptual Schema)
数据库系统的整体逻辑结构,全局视图。
包含内容:
- 所有实体、属性
- 所有关系、约束(主键、外键等)
- 全局的数据结构(比如所有表)
举例:
全局表
Student(学号, 姓名, 年龄, 性别, 专业)
Course(课程号, 名称, 学分)
SC(学号, 课程号, 成绩)
内模式(Internal Schema)
又叫物理模式(Physical Schema)。
描述数据在 物理存储 上的结构。
内容:
- 数据在磁盘上的存储方式
- 文件结构(堆文件、顺序文件)
- 索引结构(B+ 树、哈希)
- 存储路径
举例
- Student 表存储为一个堆文件
学号上建立 B+ 树索引- 每页大小为 4KB
三级结构中的两个映射
外模式——模式映射
-
一个模式可以有多个外模式,对于每个外模式有一个外模式/模式映像
-
当概念模式改变时,只要映射修改,应用程序不用改 → 实现逻辑独立性
模式——内模式映射
- 概念结构如何映射到物理存储
- 当物理存储方式改变(比如换索引结构)概念模式不改 → 实现物理独立性
数据库的“二种独立性”
逻辑独立性:当模式改变时,只需要改变外模式/模式映像,可以使外模式保持不变。
**物理独立性:**当存储结构改变时,只需要改变模式/内模式映像,可以使模式保持不变。
关系数据库
关系
关系:定义
元组:关系中的每个元素是关系中的元组,通常用
属性:关系中不同列可以对应相同的域,为了加以区分,必须对每列起一个名字,成为属性,
候选码:在一个关系中,能够唯一标识元组、并且没有多余属性的一组属性,候选码需要满足:
- 唯一性(Uniqueness)用它的值可以唯一区分任意两条记录。
- 最小性(Minimality)再去掉其中任何一个属性,都不能唯一标识元组。
一个关系可能有多个候选码,每一个都能唯一标识元组。
主码:主码指从所有候选码中选出的一个作为该关系的主键。
- 一个关系可能有多个候选码,但是主码只能选一个
- 由 DBA 或数据库设计人员选定
这些概念和数据库词汇的对应:
- 关系(relation) ↔ 表(table)
- 属性(attribute) ↔ 列(column)
- 元组(tuple) ↔ 行(row)
- 关系模式(relation schema) ↔ 表结构(列名、类型、约束)
- 关系实例(relation instance) ↔ 表中现在实际的所有行(数据)
外码:
- 外码 F 是关系 R 中的某个属性或属性组
- F 不是 R 的候选码(即不能唯一标识 R 中的元组)
- 另一关系 S 的主码 Ks 与 F 的属性类型相同或值域一致
- F 要引用 S 中的主码 Ks 中已经存在的值
因此称:
- R 是参照关系(Referencing Relation)
- S 是被参照关系 / 目标关系(Referenced Relation)
- F 是 R 的外码(Foreign Key)
外码的核心作用:建立两个表之间的联系,并保证数据的一致性。
外码是实现关系数据库中 参照完整性(Referential Integrity) 的关键。
关系完整性
实体完整性
若属性(指一个或一组属性)A 是基本关系 R 的主属性,则 A 不能取空值
参照完整性约束
若属性(或属性组)F 是基本关系 R 的外码,它与基本关系 S 的主码 Ks 相对应(基本关系 R 和 S 不一定是不同的关系),则对于 R 中的每个元组在 F 上的值必须为:
- 或者取空值
- 或者等于 S 中每个元组的主码值
用户定义的完整性
针对某一具体关系数据库的约束条件,反应某一具体应用所设计的数据必须满足的语义要求
关系代数
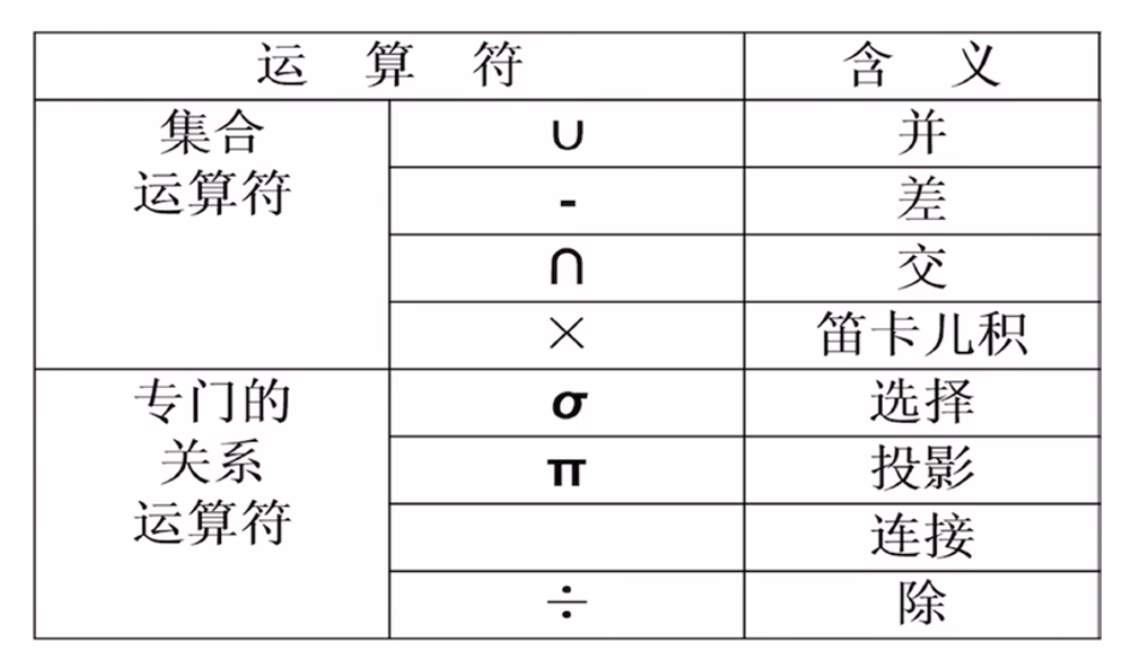
传统的集合运算:二目运算,包括交、并、差和笛卡尔积。
对于并、差和交运算,两个运算的关系必须有相同的目,且相应属性取自同一个域。
对于笛卡尔积,两个n目和m目的关系运算后得到(n+m)目的关系。

关系代数中特有的运算:
选择
- 基本形式为:
表示比较符号,可以是 等 是属性名,或常量,或函数
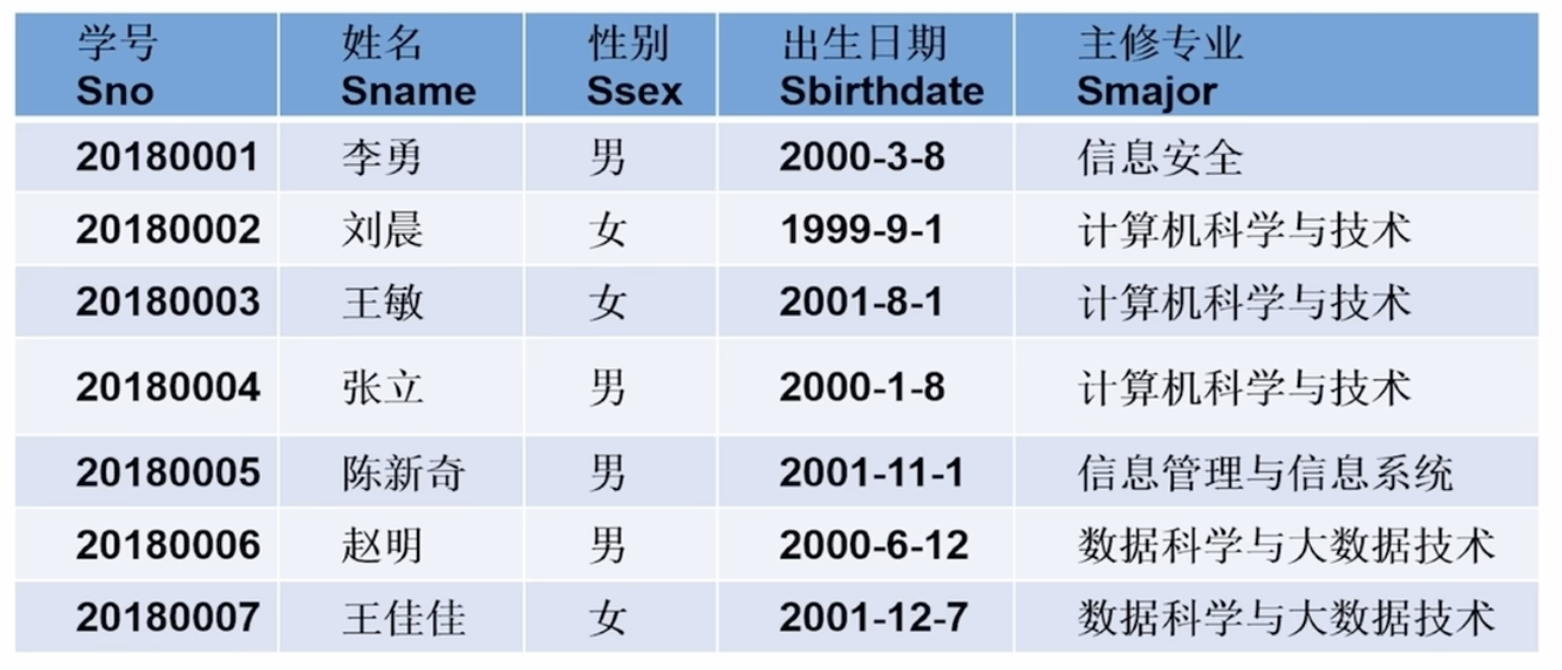
假设我们要在下面这个表中查询主修专业为信息安全的行,查询语句应该是
投影
从 R 中选择出若干属性组成新的关系
- A 是 R 中的属性列
- 投影操作主要是从列的角度进行运算
- 投影之后不仅取消了原关系中的某些列,而且还能取消某些元组
在上面那个例子中,假设我只需要姓名和主修专业,查询语句就是
连接
连接也称为
1. 等值连接
等值连接是
结果中:两个“相等的列都会保留”
会出现:R.A 和 S.B 两个重复的列,例如
的结果中会出现
- Student.学号
- SC.学号 (重复)
2. 自然连接
自动按“同名属性”做等值连接,并自动删除重复列
这里没有写条件,因为条件是系统自动识别的同名属性,所以,必须满足
- 两个关系中 至少有一个同名属性
- 连接条件自动为:所有同名属性相等
如果有:
Student(学号, 姓名)
SC(学号, 课程号, 成绩)
自然连接
3. 外连接
左外连接
- 保留 R 中所有元组
- S 中没有匹配的 → 用 NULL 填充
右外连接
- 保留 S 中所有元组
- R 中没有匹配的 → 用 NULL 填充
全外连接
- 两边的元组都完整保留
- 没匹配上的一律补 NULL
SQL 语言基础
- 数据定义:CREATE,DROP, ALTER
- 数据查询:SELECT
- 数据操纵:INSERT,UPDATE,DELETE
- 数据控制:GRANT, REVOKE
完整性约束
为什么需要数据完整性约束?
就像学校没有校规会导致秩序混乱一样,数据库没有约束就会产生错误数据。这是防止错误数据流入数据库的最后一道防线。
-
网页前端的验证(如JavaScript):相当于学校大门的保安,会进行初步检查(比如看你有没有穿校服)。
-
数据库约束:相当于教导处和班主任的最终审核,规则更严格,确保万无一失(比如检查你的成绩单是否真实有效)。
实体完整性约束 / 主键约束(PRIMARY KEY)
目标:保证表中的每一条记录都是唯一的、可识别的。
比喻:保证每个学生都有一个独一无二的学号,绝对不允许重复,也绝对不能为空。
规则: 唯一性:不允许有重复的值。 非空性:不允许为空(NULL)。 一个表最多只能有一个主键(就像一个班只能有一个学号体系)。
CREATE TABLE 学生表 (
学号 INT PRIMARY KEY, -- 学号是主键
姓名 NVARCHAR(50) NOT NULL
);
参照完整性约束 / 外键约束(FOREIGN KEY)
目标:保证表与表之间的关系是正确的。
比喻:你在“选课表”里记录某个学生选了一门课,那么,这个“学生”必须在“学生表”里存在,这门“课”也必须在“课程表”里存在。不能出现一个不存在的学生选了课。
核心概念: 主键表/被参照表:存放“权威”数据的表(如 学生表)。 外键表/参照表:引用别人数据的表(如 选课表)。 如何区分:看公共字段在哪个表里不能重复**(主键),在哪个表里可以重复(外键)。一个学生选多门课,所以“学号”在选课表里可以重复。
规则:外键字段的值必须来源于主键表的主键值,或者是NULL。
CREATE TABLE 选课表 (
选课ID INT PRIMARY KEY,
学号 INT REFERENCES 学生表(学号), -- 学号是外键,参照学生表的主键
课程号 INT REFERENCES 课程表(课程号)
);
级联操作:当设置了级联,如果主键表(学生表)中删除了一个学生,那么外键表(选课表)中所有该学生的选课记录也会被自动删除,保持数据一致性。
用户自定义完整性约束 / 检查约束
目标:根据业务需求制定特定的规则。
比喻:学校规定“学生年龄必须在16到30岁之间”或“成绩必须在0到100分之间”。
检查约束(CHECK):定义某列的值必须满足的条件。
CREATE TABLE 学生表 (
...
年龄 INT CHECK (年龄 >= 16 AND 年龄 <= 30), -- 检查约束
性别 NCHAR(1) CHECK (性别 IN ('男', '女'))
);
唯一约束(UNIQUE):保证某列的值唯一,但允许为空(NULL)。
与主键的区别:一个表只能有一个主键,但可以有多个唯一约束(比如“身份证号”字段,可以设为UNIQUE,因为它可能暂时不知道)。
默认约束(DEFAULT):如果插入数据时没指定值,就自动填充一个默认值。
CREATE TABLE 学生表 (
...
入学日期 DATETIME DEFAULT GETDATE(), -- 默认取当前系统时间
所在系 NVARCHAR(20) DEFAULT '计算机系'
);
非空约束(NOT NULL):简单直接,要求字段不能为NULL。
重要细节和技巧:
-
空值(NULL)的判断
- 判断是否为空要用
IS NULL或IS NOT NULL。 - 错误写法:
WHERE 姓名 = NULL(永远不成立)。 - 正确写法:
WHERE 姓名 IS NULL
- 判断是否为空要用
-
主键自增长
-
使用
IDENTITY(1,1)关键字,表示从1开始,每次增加1。 -
常用于主键列,这样插入数据时就不用操心主键值了,数据库会自动分配。
CREATE TABLE 学生表 ( ID INT PRIMARY KEY IDENTITY(1,1), -- 自增长主键 姓名 NVARCHAR(50) );
-
数据定义
模式定义
CREATE SCHEMA<模式名称>AUTHORIZATION <用户名>;
例如:CREATE SCHEMA AUTHORIZATION WANG; 是为用户 WANG 定义了一个 模式为 WANG 的用户名
基本表定义
CREATE TABLE<表名> (
<列名><数据类型>[<列级完整性约束>]
[,<列名><数据类型>[<列级完整性约束>]]
...
[<表级完整性约束>]
)
如果完整性约束涉及表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级

现在我们要定义一个“学生表” Student(Sno, Sname, Ssex, Sbirthdate, Smajor),Sno 是主码
CREATE TABLE Student (
Sno CHAR(10) PRIMARY KEY, -- 学号(主码)
Sname NVARCHAR(20) NOT NULL, -- 姓名
Ssex NCHAR(1) CHECK (Ssex IN ('男', '女')), -- 性别
Sbirthdate DATE, -- 出生日期
Smajor NVARCHAR(30) -- 专业
);
“课程”表:Course(Cno,Cname, Ccredit,Cpno),Cno 是主码
CREATE TABLE Course (
Cno CHAR(10) PRIMARY KEY, -- 课程号(主码)
Cname NVARCHAR(50) NOT NULL, -- 课程名
Ccredit INT CHECK (Ccredit > 0), -- 学分
Cpno CHAR(10) -- 先修课课程号
);
“学生选课表”:SC(Sno,Cno Grade, Semester, Teachingclass),Sno,Cno 是主码
CREATE TABLE SC (
Sno CHAR(10), -- 学号
Cno CHAR(10), -- 课程号
Grade INT CHECK (Grade BETWEEN 0 AND 100), -- 成绩
Semester NVARCHAR(20), -- 学期
Teachingclass NVARCHAR(30), -- 教学班
PRIMARY KEY (Sno, Cno), -- 复合主码
FOREIGN KEY (Sno) REFERENCES Student(Sno), -- 外码 → Student
FOREIGN KEY (Cno) REFERENCES Course(Cno) -- 外码 → Course
);
每一个基本表都属于某一个模式,一个模式包含多个基本表
那么如何定义基本表属于哪个模式,有三种方式
- 在定义表的时候给出,例如
Create table "S-C-SC".Student(...); - 在创建模式语句同时创建表
CREATE SCHEMA S-C-SC
CREATE TABLE Student(...)
- 设置所属模式
删除表语句:
DROP TABLE <表名> [RESTRICT|CASCADE];
- RESTRICT 删除表是有限制的
- CASCADE 删除表是没有限制的
数据查询
查询的核心思想
SELECT...
FROM...
WHERE...
SELET(选择什么):相当于告诉文件库:“我想看哪些列的信息”
- SELECT * 代表 ”我所有列都要看“
- SELECT 姓名, 年龄 表示我只看“姓名, 年龄”这两列
FROM(从哪里找)
- FROM Student 表示从 Student 这个表中找
WHERE(条件)
- WHERE 年龄 > 20
- WHERE 姓名 LIKE ‘张%’找所有姓“张”的学生(%代表任意多个字符)
- 对应的是【关系代数】里的【选择】运算,也就是过滤行
如果此时我想找出计算机系的学生的姓名和学号,那么查询语句就是
SELECT 姓名, 学号 -- 我想看姓名和学号
FROM 学生表 -- 从学生表里找
WHERE 所在系 = ‘计算机系’ -- 条件是所在系为计算机系
多表连接(JOIN ON)
如果你想查 “选修了‘数据库原理’这门课的学生姓名”。
你会发现,学生姓名在《学生表》里,而课程名称在《课程表》里。这两个表需要通过一个公共的桥梁(比如“课程号”)连起来才能查到。
这就是多表连接
SELECT 学生表.姓名
FROM 学生表
JOIN 选课表 ON 学生表.学号 = 选课表.学号 -- 通过学号连接学生表和选课表
JOIN 课程表 ON 选课表.课程号 = 课程表.课程号 -- 再通过课程号连接选课表和课程表
WHERE 课程表.课程名 = ‘数据库原理’
在 SQL Server 中,JOIN和 INNER JOIN是完全等价的,没有区别。
-- 这两种写法完全相同
SELECT * FROM A JOIN B ON A.id = B.id;
SELECT * FROM A INNER JOIN B ON A.id = B.id;
INNER JOIN(内连接)只返回两个表中有匹配关系的行。
SELECT 列1, 列2, ...
FROM 表1
INNER JOIN 表2 ON 表1.列 = 表2.列
假设有两个表:
- 左表(FROM 后面的表)
- 右表(INNER JOIN 后面的表)
INNER JOIN 只返回两个表的交集部分
但是 LEFT JOIN 会返回左表所有行,右表无匹配时显示 NULL
-- INNER JOIN:只显示选课的学生
SELECT s.Sname, sc.Cno
FROM Student s
INNER JOIN SC sc ON s.Sno = sc.Sno;
-- 结果:张三、李四、王五(假设他们都选了课)
-- LEFT JOIN:显示所有学生,包括没选课的
SELECT s.Sname, sc.Cno
FROM Student s
LEFT JOIN SC sc ON s.Sno = sc.Sno;
-- 结果:张三、李四、王五、赵六(赵六没选课,Cno显示NULL)
多个 JOIN 的连接顺序
SELECT ...
FROM A
INNER JOIN B ON A.id = B.a_id
INNER JOIN C ON B.id = C.b_id
执行顺序:A → (A+B) → (A+B+C)
实际应用技巧
- 别名简化:使用表别名(s, sc, c)让代码更简洁
- 明确连接条件:ON 子句应该明确指定连接字段
- 性能考虑:在连接字段上建立索引可以提高查询速度
分组统计(GROUP BY)
如果你想知道“每个系有多少个学生”或者“每个学生的平均分”
- GROUP BY:告诉数据库按哪个字段分组
- 聚合函数:COUNT(计数)、SUM(求和)、AVG(平均)、MAX(最大)、MIN(最小)
SELECT 所在系, COUNT(*) AS 学生人数 -- 统计每个系的行数(即学生人数)
FROM 学生表
GROUP BY 所在系 -- 按“所在系”这个字段进行分组
通过这个语句可以查询出每个系有多少个学生
运行之后,会显示,类似于:

使用 HAVING 命令可以在查询后筛选分组
如果我们只想知道学生人数超过100人的系,就可以使用
SELECT 所在系, COUNT(*) AS 学生人数
FROM 学生表
GROUP BY 所在系
HAVING COUNT(*) > 100 -- 对分组后的结果进行筛选
WHERE和 HAVING的区别
- WHERE:用于过滤行(个体),后面不能跟聚合函数
- HAVING:用于过滤组(集体),后面通常跟聚合函数
数据去重(DISTINCT)
在 SQL Server 查询语句中,去重使用的是 DISTINCT关键字。我来给你详细讲解几种常见的写法
1. 基本去重(单列)
SELECT DISTINCT 所在系
FROM 学生表
2. 多列组合去重
-- 查询不重复的系和性别组合
SELECT DISTINCT 所在系, 性别
FROM 学生表
这里是判断 (所在系, 性别)这个组合是否重复,而不是单独判断每个列。
3. 去重计数
-- 统计有多少个不重复的系
SELECT COUNT(DISTINCT 所在系) AS 系数量
FROM 学生表
4. 结合其他查询条件
-- 查询年龄大于20岁的学生来自哪些不重复的系
SELECT DISTINCT 所在系
FROM 学生表
WHERE 年龄 > 20
排序(ORDER BY)
基本语法
SELECT 列1, 列2, ...
FROM 表名
ORDER BY 列1 [ASC|DESC], 列2 [ASC|DESC], ...;
- ASC(Ascending):升序,从小到大(默认值,可以不写)
- DESC(Descending):降序,从大到小
简单排序
-- 按年龄升序(默认)
SELECT Sname, Sage
FROM Student
ORDER BY Sage; -- 或 ORDER BY Sage ASC
-- 按年龄降序
SELECT Sname, Sage
FROM Student
ORDER BY Sage DESC;
多列排序
-- 先按系别升序,再按年龄降序
SELECT Sname, Sdept, Sage
FROM Student
ORDER BY Sdept ASC, Sage DESC;
-- 结果示例:
-- 计算机系 22岁
-- 计算机系 20岁
-- 数学系 25岁
-- 数学系 19岁
限制(TOP)
TOP用于限制返回的记录数
-- 返回前N条记录
SELECT TOP N 列1, 列2, ...
FROM 表名
[WHERE 条件]
[ORDER BY 列];
-- 返回前N%的记录
SELECT TOP N PERCENT 列1, 列2, ...
FROM 表名
[WHERE 条件]
[ORDER BY 列];
一般都是和 ORDER BY 一起使用
-- 查询成绩最高的3个记录
SELECT TOP 3 s.Sname, sc.Grade
FROM Student s
JOIN SC sc ON s.Sno = sc.Sno
ORDER BY sc.Grade DESC;
-- 查询年龄最小的5个女生
SELECT TOP 5 Sname, Sage, Ssex
FROM Student
WHERE Ssex = '女'
ORDER BY Sage ASC;
数据更新
数据插入(INSERT)
INSERT INTO 表名 (字段1, 字段2, 字段3, ...)
VALUES (值1, 值2, 值3, ...);
简化写法
INSERT INTO 表名
VALUES (值1, 值2, 值3, ...);
注意:简化写法必须满足两个条件:
- VALUES 后面的必须包含所有字段的值
- 值的顺序必须与表结构完全一致
假设有学生表结构:
CREATE TABLE 学生表 (
学号 INT PRIMARY KEY,
姓名 NVARCHAR(20) NOT NULL,
年龄 INT,
所在系 NVARCHAR(30) DEFAULT '计算机系'
);
例1:插入完整数据(推荐写法)
INSERT INTO 学生表 (学号, 姓名, 年龄, 所在系)
VALUES (1001, '张三', 20, '计算机系');
例2:插入部分数据
-- 只插入学号和姓名,年龄和所在系使用默认值或NULL
INSERT INTO 学生表 (学号, 姓名)
VALUES (1002, '李四');
当插入数据时,数据库按以下规则处理
- 有明确提供值 → 使用提供的值
- 未提供值,但有默认约束 → 使用默认值
- 未提供值,无默认约束但允许NULL → 设置为NULL
- 未提供值,无默认约束且不允许NULL → 报错
数据更新(UPDATE)
UPDATE 表名
SET 字段名1 = 新值1, 字段名2 = 新值2, ...
WHERE 过滤条件;
- UPDATE:告诉数据库我要更新哪个表
- SET:具体要修改哪些字段,改成什么值
- WHERE:非常重要!指定要更新哪些行(如果不写WHERE,会更新表中所有行!)
假设有学生表:
| 学号 | 姓名 | 年龄 | 所在系 |
|---|---|---|---|
| 001 | 张三 | 20 | 计算机系 |
| 002 | 李四 | 21 | 数学系 |
| 003 | 王五 | 22 | 计算机系 |
例1:将张三的年龄改为22岁
UPDATE 学生表
SET 年龄 = 22
WHERE 姓名 = '张三';
例2:给所有计算机系的学生年龄增加1岁
UPDATE 学生表
SET 年龄 = 年龄 + 1
WHERE 所在系 = '计算机系';
例3:同时修改多个字段
UPDATE 学生表
SET 年龄 = 23, 所在系 = '软件工程系'
WHERE 学号 = '001';
数据删除(DELETE)
DELETE [FROM] 表名
WHERE 过滤条件;
- FROM关键字可以省略
例1:删除学号为003的学生记录
DELETE FROM 学生表
WHERE 学号 = '003';
例2:删除所有数学系的学生
DELETE 学生表 -- 这里省略了FROM
WHERE 所在系 = '数学系';
同时,我们还能结合子查询的更新/删除
例1:删除没有选任何课程的学生
使用子查询:
DELETE FROM 学生表
WHERE 学号 NOT IN (SELECT DISTINCT 学号 FROM 选课表);
使用表连接:
DELETE S
FROM 学生表 S
LEFT JOIN 选课表 SC ON S.学号 = SC.学号
WHERE SC.学号 IS NULL;
例2:将计算机系学生的成绩都增加5分
UPDATE 选课表
SET 成绩 = 成绩 + 5
WHERE 学号 IN (
SELECT 学号 FROM 学生表
WHERE 所在系 = '计算机系'
);
索引
索引是一种特殊的数据库对象,它不直接存储数据,而是存储数据的位置信息(就像书的目录不存储章节内容,只告诉你内容在哪一页)
为什么要用索引?
优点:
- 极大提高查询速度:特别是当表中有大量数据时
- 提高ORDER BY、GROUP BY等操作的效率
缺点:
- 占用额外磁盘空间
- 降低增删改的速度(因为维护索引需要时间)
当你创建主键(PRIMARY KEY) 或唯一约束(UNIQUE) 时,SQL Server会自动为这些列创建索引
索引的三种分类
(1) 聚集索引 vs 非聚集索引
| 特性 | 聚集索引 | 非聚集索引 |
|---|---|---|
| 数量 | 每个表只能有1个 | 每个表可以有多个 |
| 数据顺序 | 索引顺序 = 数据物理存储顺序 | 索引顺序 ≠ 数据物理存储顺序 |
| 速度 | 更快(直接定位数据) | 稍慢(需要二次查找) |
| 比喻 | 汉语字典的拼音排序(内容按拼音排) | 汉语字典的笔画检索表(检索表单独存在) |
(2) 唯一索引 vs 非唯一索引
- 唯一索引:索引列的值必须唯一(如主键、唯一约束创建的索引)
- 非唯一索引:允许索引列有重复值
(3) 单列索引 vs 多列索引
- 单列索引:只基于一个字段创建
- 多列索引:基于多个字段组合创建(要注意字段顺序)
创建索引的语法
-- 创建聚集索引(每个表只能有一个)
CREATE CLUSTERED INDEX IX_学生表_学号
ON 学生表(学号);
-- 创建非聚集索引(默认就是非聚集的)
CREATE INDEX IX_学生表_姓名
ON 学生表(姓名);
-- 创建多列非聚集索引
CREATE INDEX IX_学生表_系别年龄
ON 学生表(所在系, 年龄);
适合创建索引的场合:
- 经常用于
WHERE条件的字段(如:WHERE 学号 = '001') - 经常用于
ORDER BY、GROUP BY的字段 - 经常用于表连接的公共字段
- 重复值较少的字段
不适合创建索引的场合:
- 数据量很小的表
- 频繁进行增删改操作的表
- 重复值很多的字段(如:性别,只有"男"/"女")
- 很少用于查询的字段
视图
视图是一个虚拟表,它不实际存储数据,只保存一个查询定义。当你查询视图时,数据库会执行这个查询并返回结果。
把视图想象成一张 “定制好的报表” 或者 “预存的查询结果”
想象一下,你是公司的老板,你的数据库里有一张巨大的《员工信息总表》,里面包含所有信息:
- 员工 ID
- 姓名
- 部门
- 工资
- 电话号码
- 家庭住址
- ...等等几十个字段
现在,你需要给部门经理看数据,但会出现什么问题?
-
信息太杂乱:经理可能只关心他本部门的员工,不想看到全公司的人。
-
数据太敏感:经理不应该看到所有员工的工资和家庭住址。
这时候,“视图”就派上用场了!
你可以为销售部经理创建一个视图,叫 V_销售部员工通讯录。
创建这个视图的“配方”(SQL语句)是这样的:
CREATE VIEW V_销售部员工通讯录
AS
SELECT 姓名, 部门, 电话号码 -- 只选择姓名、部门、电话这三个字段
FROM 员工信息总表
WHERE 部门 = '销售部'; -- 只筛选出销售部的员工
这个“视图”有什么神奇的效果?
-
它不存储数据:这个视图本身不占用空间,它只是存了上面那个“查询配方”。
-
它像一张虚拟的表:当销售部经理想要查看数据时,他只需要输入:
SELECT * FROM V_销售部员工通讯录;数据库会立刻按照存好的“配方”去《员工信息总表》里找出销售部员工的姓名和电话,然后生成一张临时的、干净的表格给他看
-
他看到的只是结果:经理根本看不到工资、住址等敏感信息,也看不到其他部门的员工。他感觉就像在查询一张独立的《销售部通讯录》表一样简单。
视图的实际例子
例1:创建学生基本信息视图
CREATE VIEW V_学生基本信息
AS
SELECT 学号, 姓名, 年龄, 所在系
FROM 学生表
WHERE 所在系 = '计算机系';
使用视图
-- 像查询普通表一样查询视图
SELECT * FROM V_学生基本信息;
例2:创建带计算列的视图(必须取别名)
CREATE VIEW V_学生统计
AS
SELECT
所在系,
COUNT(*) AS 学生人数,
AVG(年龄) AS 平均年龄
FROM 学生表
GROUP BY 所在系;
视图的数据修改规则
通过视图可以修改基表数据,但有限制:
可以修改的情况:
- 视图来源于单个表
- 不包含聚合函数、计算列等
不能修改的情况:
-- 这个视图的数据不能直接修改
CREATE VIEW V_平均年龄
AS
SELECT 所在系, AVG(年龄) AS 平均年龄
FROM 学生表
GROUP BY 所在系;
-- 错误:UPDATE V_平均年龄 SET 平均年龄 = 20 (不允许!)
视图的高级选项
(1) 加密视图定义
CREATE VIEW V_加密视图
WITH ENCRYPTION -- 加密,别人看不到视图的定义
AS
SELECT 学号, 姓名 FROM 学生表;
(2) 强制检查约束
CREATE VIEW V_计算机系学生
AS
SELECT * FROM 学生表 WHERE 所在系 = '计算机系'
WITH CHECK OPTION; -- 通过该视图插入的数据必须满足WHERE条件
视图的三大作用
- 简化复杂查询:将复杂的多表连接查询封装成视图,用户直接查询视图即可
- 聚焦重点数据:只暴露用户关心的字段,隐藏敏感或不相关字段
- 提高安全性:限制用户只能访问视图,而不能直接访问底层表
规范化理论
为什么要规范化
想象一下,你们学校用一个巨大的Excel文件来管理所有信息,这个文件包含:
- 学号、学生姓名、系名称、系主任、课程号、课程名、成绩
| 学号 | 学生姓名 | 系名称 | 系主任 | 课程号 | 课程名 | 成绩 |
|---|---|---|---|---|---|---|
| 001 | 张三 | 计算机系 | 李主任 | C01 | 数据库 | 90 |
| 001 | 张三 | 计算机系 | 李主任 | C02 | 操作系统 | 85 |
| 002 | 李四 | 计算机系 | 李主任 | C01 | 数据库 | 92 |
| 003 | 王五 | 数学系 | 王主任 | M01 | 高等数学 | 88 |
这张表虽然直观,但存在三大致命问题
- 数据冗余:张三选了2门课,他的“系名称”和“系主任”信息就被重复存储了两次。李主任的名字存储了无数次!
- 插入异常:我想新增一个“物理系”,系主任是“赵主任”。但因为没有学生选修任何课程,我就无法插入这条信息(因为学号、课程号等主键为空)。
- 删除异常:如果学生“王五”毕业了,我们删除他的记录,结果“数学系”和“王主任”的信息也从数据库中消失了。
- 更新复杂:如果“计算机系”换主任了,我必须修改表中所有“计算机系”对应的记录,万一漏改一处,就会导致数据不一致(有的地方是李主任,有的地方是新主任)。
规范化就是要解决这些问题 它的核心思想是:“一个表只干一件事”,通过拆分表来消除冗余和操作异常。
函数依赖
这是理解范式的钥匙。它的意思很简单:在一个表中,如果我知道了A的值,就能唯一确定B的值,我们就说B函数依赖于A。
记作: A → B
-
在你身份证号码(A)确定的情况下,你的姓名(B)也就确定了。所以
身份证号 → 姓名。 -
但是,知道你的姓名(B),不能确定你的身份证号(A),因为可能有重名的人。所以
姓名 → 身份证号不成立。
层层递进的范式
范式就像游戏的关卡,一级比一级要求严格。满足第二范式,必须先满足第一范式。
第1范式(1NF):原子性,列不可再分
表中的每个字段都是不可分割的最小单元。
一个“联系方式”字段里存了“手机:138xxx,电话:010-1234”。这就不满足1NF。
解决方法: 拆分成“手机号”和“固定电话”两个单独的字段。
1NF是关系数据库的最基本要求,我们通常接触的表都满足1NF
第2范式(2NF):消除部分依赖
前提 满足1NF。
要求 所有非主属性必须完全依赖于整个主键,而不能只依赖于主键的一部分
- 主属性:包含在任一候选码中的属性
- 非主属性:不包含在任何候选码中的属性
违反2NF的例子,(回头看我们的大表)
假设主键是(学号,课程号)。因为只有同时知道学号和课程号,才能确定成绩。
- 完全依赖:
成绩完全依赖于整个主键(学号,课程号)。 - 部分依赖:
学生姓名只依赖于主键中的学号,与课程号无关。系主任只依赖于学号(通过系名称)。这就是部分函数依赖!
解决方法 拆分表!
- 学生表(学号,学生姓名,系名称,系主任) <- 主键是
学号 - 选课表(学号,课程号,成绩)<- 主键是
(学号,课程号)
拆分后,在学生表里,学生姓名、系名称就完全依赖于主键学号了。冗余和异常都被消除!
第3范式(3NF):消除传递依赖
前提:满足2NF。
要求:所有非主属性必须直接依赖于主键,而不能通过其他非主属性间接依赖。
违反3NF的例子(看我们拆分后的学生表):
学生表(学号,学生姓名,系名称,系主任)
- 学号 → 系名称(一个学生属于一个系)
- 系名称 → 系主任(一个系有一个主任)
- 所以,
学号 → 系主任是传递函数依赖!系主任不是直接依赖于学号,而是通过系名称传递过来的。
带来的问题:如果计算机系有1000个学生,李主任的名字还是会被重复存储1000次!仍然有冗余。
解决方法:继续拆分!
- 学生表(学号,学生姓名,系名称) <- 主键是
学号 - 系表(系名称,系主任) <- 主键是
系名称
现在,每个表都满足“一个表只干一件事”,完全消除了传递依赖。
经过规范化(2NF, 3NF)后,我们最初的那张大表被拆分成了4张表:
- 学生表(学号,学生姓名,系名称)
- 课程表(课程号,课程名)
- 选课表(学号,课程号,成绩)
- 系表(系名称,系主任)
这个设计完美地解决了所有问题:
- 冗余极小:每个信息只存储一次。
- 无插入异常:可以单独添加一个尚未有学生的系。
- 无删除异常:删除一个学生不会带走整个系的信息。
- 更新简单:改系主任只需在
系表中修改一次。
| 范式 | 核心要求 | 要消灭的敌人 | 解决方法 |
|---|---|---|---|
| 1NF | 字段原子性 | 大杂烩字段 | 拆分字段 |
| 2NF | 完全依赖 | 部分函数依赖(非主属性依赖部分主键) | 拆分表 |
| 3NF | 直接依赖 | 传递函数依赖(非主属性间接依赖主键) | 再拆分表 |
规范化的终极目标就是通过拆分,让每个表的概念更单一,从而保证数据的一致性,减少冗余。一般在实践中,达到第三范式(3NF)就是一个非常优秀和实用的设计了。