随机变量
离散型随机变量
先来看一个启发性的例子,我们把一个均匀的硬币投掷了三次,设投出正面为 ,反面为 ,能很轻松得得到结果空间:
中的每个元素的概率都是 ,于是我们得到了结果空间和概率函数
如果现在我们提出一个问题:对于一个抛掷序列,我们能否得到一个抛掷序列,求出它正面出现的次数
这可以用一个函数来表示,我们定义一个从 到实数集 的函数 ,其中 等于 中正面出现的次数,例如:,
同理,我们也可以定义反面出现的次数 ,一个比较显然的结论就是 因为我们一共抛掷了 次
我们可以同时定义三个简单函数来构造 ,定义 ,表示如果第 次掷出的正面,那么 ,否则为 ,例如 ,于是可以得出等式
这个例子体现了我们可以用较简单的函数来构造复杂的函数,接下来给出随机变量的定义
::: tip 定义
离散型随机变量 是定义在一个离散的结果空间 上的实质函数,具体地说,我们为每个元素 指定了一个实数
:::
(这里的离散型也叫概率密度函数,在中国也叫分布律)
我们通过一个函数 把结果空间上的值映射到了实数域上,一个很自然的问题就是求 ,随机变量的值恰好是 的概率是多少
在上面的例子中,由于都是等概率的,所以我们只需要数出 出现了几次,除以 就是概率,可以得到
除了这四个值,其他地方的概率都是 ,于是我们引出了 概率密度函数(probability density function, PDF)的定义
::: tip 定义
设 是一个随机变量,它定义在离散结果空间 上,那么 的概率密度函数就是 取某个特定值的概率:
:::
另外一个重要的概念是 累积分布函数(cumulative distribution function, CDF),虽然这个在概念对连续型随机变量更有用, 但它在离散型随机变量方面仍有些用途
::: tip 定义
设 是一个随机变量,它定义在离散结果空间 上,那么 的累积分布函数就是 不超过特定值的概率:
:::
连续型随机变量
和离散型随机变量相似,我们尝试在结果空间里面定义一个随机变量,但实际上这比结果空间 是有限的或可数的情况要更困难一些
一个概率空间由三部分组成:结果空间 ,概率函数 ,以及 有定义的子集构成的 代数,( 在其他子集上无定义)
::: tip 定义
设 是一个随机变量,如果存在一个实值函数 满足:
- 是一个连续分段函数
那么 是一个连续性随机变量, 是 的概率密度函数
的累计分布函数 就是 不大于 的概率:
:::
下面来看一个例子,尝试验证它是否满足连续性随机变量的三个条件:分段连续、非负性,积分为
分段连续:这个函数显然是分段连续的
非负性:
由于 ,
积分:
可以看出积分不为 ,所以 不是一个概率密度函数
很容易想到用一个常数对他进行缩放,使它积分值为
那么 的就是一个概率密度函数
常见分布
柏松分布
::: tip 定义
设随机变量 的取值为 对应的分布律是:
则称随机变量 服从参数为 的柏松分布,记为
:::
泊松分布还有一个非常有用的性质,即它可以作为二项分布的一种近似,在二项分布计算中,当 n 较大时计算结果非常不理想,如果 比较小,而 适中时,我们常用柏松分布的概率值近似取代二项分布的概率值,因为柏松分布要好算很多
::: tip 柏松定理
当 ,有 ,则
:::
超几何分布
::: tip 定义
设有 件产品,其中 件是不合格品,若从中不放回地抽取 件,设其中含有的不合格品的件数为 ,则 的分布律为:
则称 服从参数为 和 的超几何分布,记为
:::
若将不放回改为有放回,那就变成 重伯努利试验了,就是二项分布,当 非常大时,有放回和不放回的分布相差很小,所以可以证明:当
几何分布
在伯努利试验中,记每次试验中 事件发生的概率
::: tip 定义
设随机变量 表示 事件首次出现时已经试验的次数,则 的取值为 ,对应的分布律为:
则称随机变量 服从参数为 的几何分布,记为
:::
负二项分布
::: tip 定义
在伯努利试验中,记每次试验中 事件的概率 ,设随机变量 表示 事件第 次出现时已经试验的次数,则 的取值为 ,对应的分布律为:
则称随机变量 服从参数 的负二项分布,记为 ,当 时,就是几何分布
:::
这个式子可以理解为,前 次,出现了 次事件 ,最后一次是事件 ,乘上概率
均匀分布
::: tip 定义
设 为随机变量,对任意两个实数 ,概率密度函数为:
:::
指数分布
::: tip 定义
设 为随机变量,概率密度函数为:
则称随机变量 服从参数为 的指数分布,记为
相对应的分布函数为:
:::
指数分布同几何分布相似, 也具有无记忆性
正态分布
::: tip 定义
设 为随机变量,概率密度函数为:
则称随机变量 服从参数为 和 的正态分布,记为
相应的分布函数为
:::
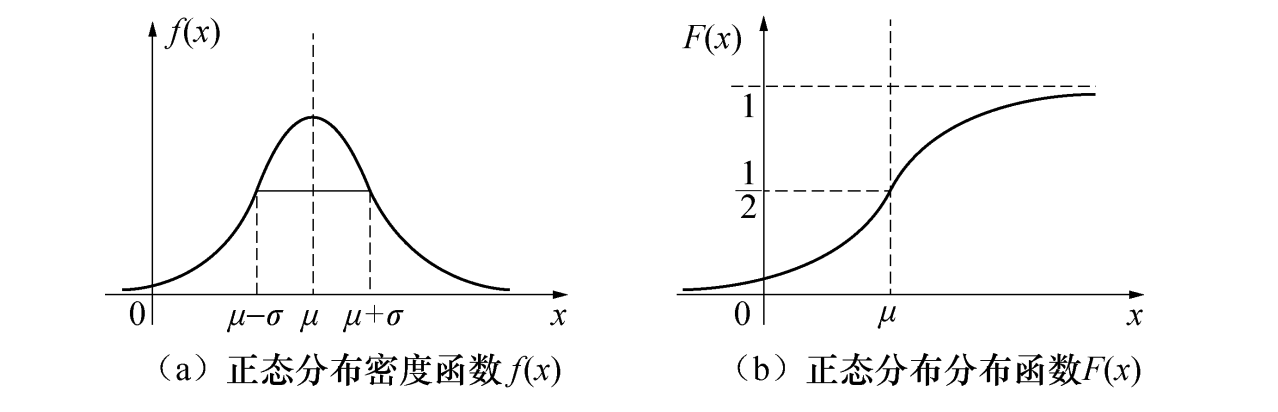
- 正态分布是一个倒钟形曲线,左右两边关于 对称
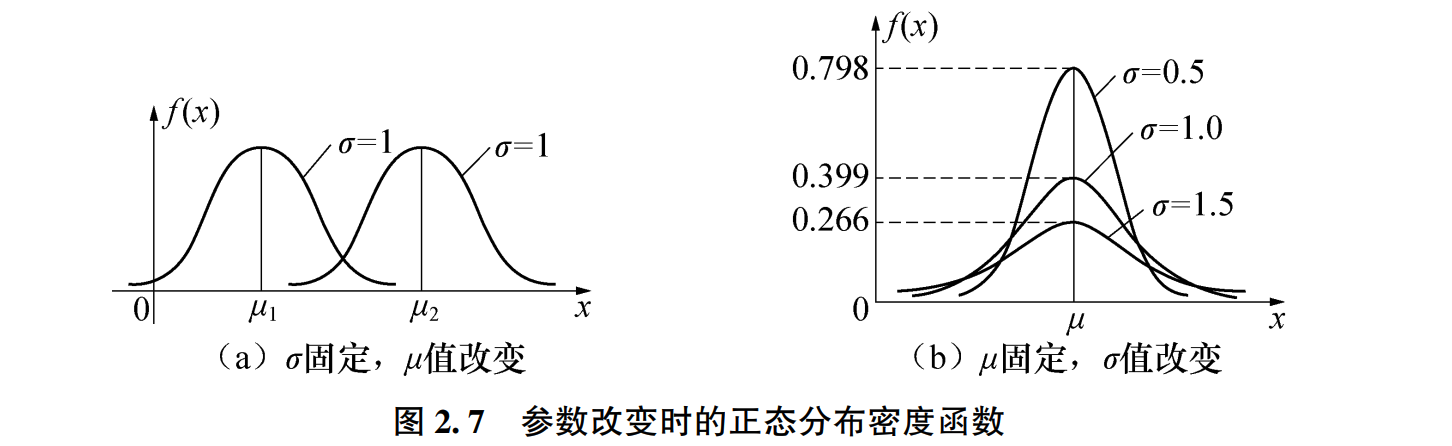
- 当 时, 取得最大值 这个值随着 增大而减小
- 固定 ,改变 曲线沿着 平移,但不改变形状,所以 又被称为位置参数
- 固定 ,改变 的值,曲线的位置不变,随着 越小,曲线越陡峭,参数 又被称为尺度参数
特别的,当 时,对应的正态分布被称为标准正态分布,记为 概率密度函数和分布函数为:
一般来说,对于标准正态分布可以通过查表得到值。
当 时,标准正态分布函数 ,利用正态分布的概率密度函数 是偶函数的性质得:
对于任意的两个实数 可得
若随机变量 ,则 ,所以,对任意两个实数 ,有:
卷积和变量替换
如果我们想要把随机变量之间进行运算,例如我们想把 和 的概率密度函数过渡到 的密度并不容易
如果我们有两个随机变量 和另外一个随机变量 ,我们想知道 的概率密度是多少,给出 和 的概率密度函数
如果我们有 ,那么 就始终为 ,如果 那么
于是可以得出一个启示:只知道 和 是不足以确定 的,但如果 和 是独立的,那么就可以得出来
::: tip 定义
设 和 是定义在 上的两个 相互独立 的连续性随机变量,它们的概率密度函数分别是 和 , 和 的卷积记作 ,表达式为
如果 和 都是离散型随机变量,那么
:::
通过卷积,就可以求得 的 PDF
::: tip 定理
设 和 是定义在 上的两个相互独立的随机变量,它们的概率密度函数分别是 和 如果 ,那么
另外卷积是可以交换的,也就是说:
:::
证明 这里给出连续性的证明
我们的思路是通过求累积分布函数来求出概率密度函数,有
不妨设 的值是 ,我们要求 也就是
让 取遍 的所有可能值,有
然后对累积分布函数求导得到概率密度函数
观察一些卷积的例子
::: note 例题
抛掷两颗均匀的骰子,假设两颗骰子掷出的结果是相对独立的,让 表示第一颗骰子掷出的数字, 表示第二颗骰子掷出的数字,有:
求 的概率密度函数
:::
根据卷积的定义可知,,那么
考虑范围
我们可以把 在这里看出常数,所以 的有效取之范围是
例如,当 ,那么 当值可能的取值是
所以得到答案
现在考虑多变量的卷积,能不能求出 ?
::: tip 定理
设 是相互独立的随机变量,他们的概率密度函数分别是 ,那么有
其中
:::
我们已经证明了卷积是可交换的,也就是说 ,另外卷积是满足结合律的:
需要注意,卷积需要用两个函数作为输入,并返回一个函数作为输出,对于 就需要小心了,我们不能直接对三个函数求卷积,我们需要说明是: 或者是 ,幸运是的,由于结合律,这两个值相同,但是仍要说明运算顺序
下面来看一下上面那个定义的证明
证明:我们只考虑 的情况,一般情况下可以类似得证明
我们假设 ,由于 分别和 独立,所以 和 独立,于是有
当然 可以写成 ,得到
这里还是利用了加法的交换律来证明结合律
变量替换公式
假设有一个连续性随机变量 ,它的概率密度函数是 ,如果 是一个合适的函数,那么我们能求出 的概率密度函数
::: tip 定理
设 是一个概率密度函数为 的连续性随机变量,并存在一个区间 使得当 时,
设 是一个可微函数,其反函数是 ,除了在有限多个点的导数值可能为 外, 的导数在 中始终为正或始终为负,如果 ,那么
:::
来再解释一下这个定理
- 使得当 时, 其实是在缩小研究范围,当 在 中取值的时候,概率函数不为 ,我们需要的函数只需要在研究范围 内有良好的性质,不需要在 上有良好的性质
- 其次要满足 是可微的,例如 就不行,但是如果把 就满足条件了
- 最后要求除了在个别点能为 外, 的导数值要么始终为正,要么始终为负,就是说明要么单增,要么单减
回顾一下反函数,如果 是 的反函数,满足:,且 ,后面那个式子对 求微分可以得到
也就是说我们需要求 的导数然后把 带入就好了
::: note 例题
设 的概率密度函数是:
并设
:::
- 区间
- 除了 点以外, 单增
- ,
套用公式 得到
检验一下,显然这个函数是非负的,查看积分是否为
考虑证明变量替换公式
证明 思路还是先求累积分布函数,然后对累积分布函数求导得到概率密度函数
情形一: 假设 是正的,所以 被映射成 那么,由 等价于 可知
于是,有
使用链式法则对 求导
情形二: 假设 是负的,所以 被映射成 ,此时, 变成了 ,有
设 ,得到
用链式法则对 求导
这里 是负的,所以 也是负的
所以结合情况一,能得到总的式子
证毕
这样一个通用的累积函数的方法也可以作为求变量替换的通法
微分恒等式
假设我们需要求:
的值
我们发现这个和几何级数很像,但不完全相同,一个的分子是 一个分子是
我们有几何级数的公式,我们可以对等式两端进行一些运算,从而得出新的恒等式
我们已知几何级数恒等式
我们再抽象一层,把这个 换成 ,考虑更一般的情形,也就是要求
我们有几何恒等式
在两边乘上 ,得到
想要得到 ,只需要在等式两边乘 得到
带入 可以得到和就是
然后思考另外一个问题,如何求
还是从几何级数开始,两边乘上 ,得到
然后再在两边乘上 ,得到
下面给出定义:
::: tip 定义:微分恒等式法
设 是一些参数,设
其中, 和 都是 的可微函数,如果 退化到求和与微分次序可以交换,那么
:::
使用微分恒等式能给我们更多解题思路
来看一下微分恒等式在二项分布随机变量上的应用,有二项分布
我们设 ,于是二项分布就变成
这里我们把 看称相互独立的变量,以为如果把 限定死的话,和就恒为 ,他的导数就是 ,没有研究的意义了
假设现在我们需要求
我们在等式两端乘上 得到
现在回代 ,得到
现在我们需要计算方差
后面一个均值我们已经得到了,现在需要得到 的值
我们从二项展开那个等式开始
在两边乘上 得到
再次乘上 得到
另 ,上式就变成了
于是我们能算出方差了
现在再来观察一下在正态分布随机变量上的应用
/
表示 服从均值为 ,方差为 的正态分布,概率密度函数是
我们现在只考虑标准正态分布
那么他的 阶矩为
显然,当 为奇数的时候,这是一个奇函数,积分为 ,我们必须要考虑 为偶数的情况,处理方法至少有两种:直接积分和微分恒等式
直接积分
考虑方差,由于均值是 ,所以方差为
令
得到了, 和 ,于是有
于是我们证明了二阶矩为
微分恒等式法
我们从这个事实开始
把 移动到另外一遍得到
我们把 用于上式两端,为什么要乘上 因为微分会对 产生影响,从而产生 的因子,所以需要乘上
令
这样我们就得出了
此外,积分 与标准正态分布的矩 之间存在一种简单的关系:
这里可以看出 是均值为 且方差为 的正态分布的 阶矩
我们证明了
我们在上面那个积分两端再乘上 得
等价于
将 再次乘在式子两端,我们有
令 可以得到标准正态分布的矩的公式
多维随机变量
::: tip 定义
设有随机试验 ,其样本空间为 ,若 中的每一个样本点 都有一对实数 与其对应,则称 为二维数组随机变量
:::
联合分布函数
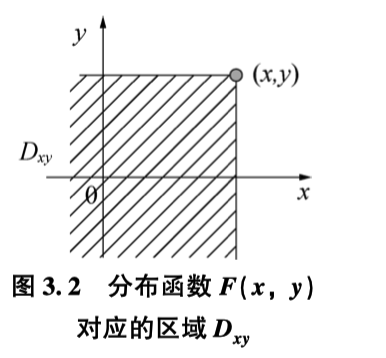
可以理解为前缀和
::: tip 定义
设 为二维随机变量,对任意的 ,称
为随机变量 的联合分布函数
:::
联合密度函数
::: tip 定义
设二位变量 的联合分布函数为 ,如果存在一个二元非负实值函数 ,使得对于任意 有
成立,则称 为二维连续性随机变量, 为二维连续性随机变量 的联合密度函数
:::
几何意义就是左前侧阴影部分的体积

常见分布
二维均匀分布
::: tip 定义
设二维随机变量 的联合密度函数为
其中 是 平面上的某个区域, 为 的面积,则称 服从区域 上的二维均匀分布
:::
二维正态分布
::: tip 定义
如果 的联合密度函数为
则称 服从二维正态分布,记为
:::
边缘分布
如果知道二维随机变量 的联合分布,那么其中一个变量的分布肯定也能知道
边缘分布函数
::: tip 定义
设二维随机变量 的联合分布函数为 ,称
为随机变量 的边缘分布函数,随机变量 的边缘分布函数同理
:::
离散型边缘分布律
求 的边缘分布律即为求 联合分布律表格中的行和, 的边缘分布律即为求 联合分布律表格中的列和
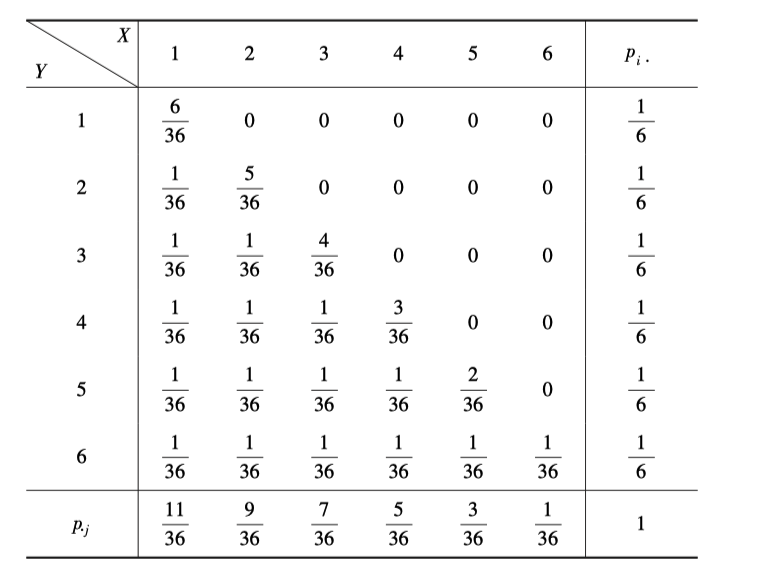
的边缘分布律为

的边缘分布律为

连续性边缘密度函数
定义 设二维连续型随机变量 的联合密度函数 ,则 的边缘密度函数为
的边缘密度函数类似
相互独立性
::: tip 定义
设 为二维随机变量,若对任意的 ,有:
成立,则称随机变量 与 相互独立
:::
::: tip 定理
设 为二维离散型随机变量, 和 相互独立的充分必要条件是,对任意的 ,都有:
成立
:::
条件分布
离散型条件分布律
::: tip 定义
设二维随机变量 ,其联合分布律为:
关于 的边缘分布律为 ,称
为在 的条件下随机变量 的条件分布律
同理,关于 的边缘分布律为 ,称
为在 的条件下随机变量 的条件分布律
:::
连续性条件概率密度
先来看一个例子,二维随机变量 的概率密度为
求概率
如果强行使用离散型的分析方法 会发现 ,除数不能为 ,肯定有问题
所以不能直接带入条件概率公式,需要先求得概率密度函数,然后通过概率密度函数求条件概率密度函数
::: tip 定义
设二维连续性随机变量 的联合概率密度为 ,其关于 的边缘概率密度分别为 和 ,则称
为给定 的条件下, 的概率密度函数
为给定 的条件下, 的概率分布函数
:::
随机变量的数字特征
数学期望和矩
::: tip 定义
设 是定义在 上的随机变量,他的概率密度函数是 ,函数 的期望值是
最重要的情形是 ,我们把 称为 的 阶矩,把 称为 的 阶中心矩
:::
只要能算出和或积分, 就可以求出期望值和矩
最重要的两个矩:
::: note 例题
- 求 阶矩
- 的期望
- 的期望
:::
- 求 时候的 阶矩,就是求
- 求 的期望,就是计算积分
这里有三个积分,我们需要一一处理
第一个积分就是:
第二个积分需要使用分部积分法
第三个积分同样也适用分部积分法
最后把三个积分结合在一起
- 求 的期望,也是积分
但是积分 不存在,所以这个期望也不存在
均值和方差
一阶矩和二阶中心距是最重要的两个矩. 这两个重要的矩分别有自己的名称:均值和方差
::: tip 定义
设 是一个随机变量,它的概率密度函数是
- 的 均值 是一阶矩,我们把他称为 或
- 的 方差 是二阶中心矩,计作 或 ,也可以说是 的期望
为了保证均值存在,我们希望 或 是有限的
:::
均值就是期望值或平均值,如果从分布中不断地取出很多值,然后对得到的结果求平均值,那么这个平均值应该非常接近于
标准差可以预测出结果与均值之间差距的波动程度,标准差越小,结果就越容易分布在均值附近
与方差相比,标准差的优势在于它和均值有相同的单位,因此,标准差是衡量结果在均值附近波动幅度的自然尺度
::: note 例题
抛掷两颗均匀的骰子,随机变量 表示掷出的数字之和,我们给出 的 PDF(概率密度函数)
求均值,方差,标准差
:::
就是套公式
期望的线性性质
有一个最重要且最实用的事实:期望是线性的
::: tip 定理
设 是随机变量,并设 是满足条件: 有限
令 表示任意实数,那么
注意:这里的随机变量不一定是相互独立的
:::
用文字来描述,就是 “和的期望等于期望的和”
下面有几个利用这个性质推理出的几条关键结果
::: tip 定理
设 是一个随机变量,它的均值为 ,方差为 ,如果 和 是任意两个固定的常数,那么随机变量 有如下结果
:::
感性理解上也很对,如果随机变量缩放 倍,那么均值也被缩放 倍,标准差被缩放 倍,方差被缩放 倍
::: tip 定理
设 是一个随机变量,那么
:::
证明:由于期望具有线性性质
这是一个很好的公式,能让我们在已知一阶矩和二阶矩的前提下,利用这个公式得出二阶中心矩
均值和方差的性质
我们先称述一个重要的有用的事实
::: tip 定理
如果 和 是相互独立的随机变量,那么
一种特殊的情况是
:::
证明:前面的线性性质讲的是和,但这里是积
如果两个相互独立的随机变量,那么联合概率密度函数就等于它们边缘概率密度函数之积,即
把上面这个式子应用到二重积分中
证毕
再来看一个很好的性质
::: tip 定理
设 是 个随机变量,它们的均值是 ,方差是 ,如果 ,那么
如果随机变量是 相互独立 的,那么有:
:::
这里需要特别注意第二个性质成立的条件,相互独立,很容易忘记
下面给出一个这个定理的应用
假设有两只收益可变的股票,它们每股的价值是 ,两支股票的平均收益是 ,它们的方差都是 ,我们的目标是建立一个收益尽可能多且风险尽可能少的投资组合,我们假设这两只股票是相对独立的
假设我们一共投资 元,其中的 元来买第一支股票,剩下的 来买第二只,设
先来看期望:
的变化显然不能提升我们的期望收益
再考虑方差:
这里可以看出,投资的方差取决于 ,当 时,方差取到最小值为
协方差和相关系数
::: tip 定义 协方差
设 和 是两个随机变量, 和 的协方差记做 或者
当 都是随机变量,而且 ,那么
:::
和前面那个定理不同的是,我们没有选择用独立性把交叉项消去,而是保留下来,它们就是协方差
与协方差密切相关的术语是相关系数,相关系数
相关系数是对协方差的标准化,我们有 ,相关系数越接近 或 ,线性相关性就越强
对于任意两个随机变量 和 ,如果它们的均值分别是 和 ,那么 和 的协方差可以写成
这个式子和求方差的公式非常像,可以利用期望的线性性质证明
统计量
总体、样本和统计量
在一个统计问题中,把研究对象的全体称为总体,构成总体的每个成员称为个体
比如,研究某学校的身高情况,全体身高就是总体,每个学生的身高就是个体
::: tip 定义 样本
若样本 为所考察的总体具体相同的分布,且 相互独立,则称 为来自总体 ,容量为 的简单随机样本,简称样本
:::
设总体 是一个离散型的随机变量,分布律为 ,样本 的联合分布律为
就是各个部分乘起来,连续性的概率也是一样的
一旦给执行随机抽样之后,样本就是一组数据,用小写的英文字母 表示,也称之为样本观测值,样本观测值 就是样本 的一组特定的观测值
::: tip 定义 统计量
设 为取自总体的一个样本,样本 的函数为 ,若 中不直接包含总体分布中的如何未知参数,则称 为统计量
:::
常见的统计量